
Desarrollo de Script en Python para Bajar imágenes y Peticiones a Servicio REST
Para los que vivimos en Honduras, el pasado 28 de noviembre fueron las elecciones en este pedazo de tierra. Como buena costumbre latinoamericana, los rumores de fraude no se hicieron esperar. Posteriormente, realizaré un análisis tecnológico de las elecciones. Sólo para mostrar que los políticos no son las personas más inteligentes del país y que a la mayoría de ellos no les gusta rodearse de inteligentes (los geeks nos sentimos marginados…. ay! casi lloro!)
El viernes, estaba algo aburrido y me puse a ver los últimos de la casa de papel (Que mal final, maldita sea). Pues la eso El viernes, estaba algo aburrido y me puse a ver los últimos episodios de la casa de papel (Que mal final, maldita sea). Pues eso no me quitó el aburrimiento y entré a Facebook, empecé a ver varios Posts comentando el gran fraude electoral a nivel legislativo. Como todo buen programador con TOC, me puse a ver la página de los resultados (La puedes ver acá), con el objetivo de encontrar irregularidades al analizar los datos. Sin embargo, la página no tenía una opción para bajar todos los datos, por lo cual se tendría que ir página por página. Esto pues no es eficiente y tomaría demasiado tiempo, pero como dijo un hombre sabio alguna vez:
«Encontraremos un camino… Y si no, lo crearemos»
Requerimientos
Para poder realizar un análisis de cualquier tipo, es necesario obtener los datos. La página ofrece la opción de visualizar la información correspondiente a un centro y el nivel electoral de cada uno (Recordar que son 3 niveles), adicionalmente podemos observar el acta original resumida en formato de imagen. Ambas fuentes son valiosas, debido a que, si encontramos alguna anomalía en los datos, se puede verificar en la imagen si fue un “error de dedo”. Para poder visualizar esta información en la página debemos seleccionar el filtro de la ubicación y ahí podemos ver la data correspondiente con su respectivo botón para bajar la imagen del acta.

Análisis
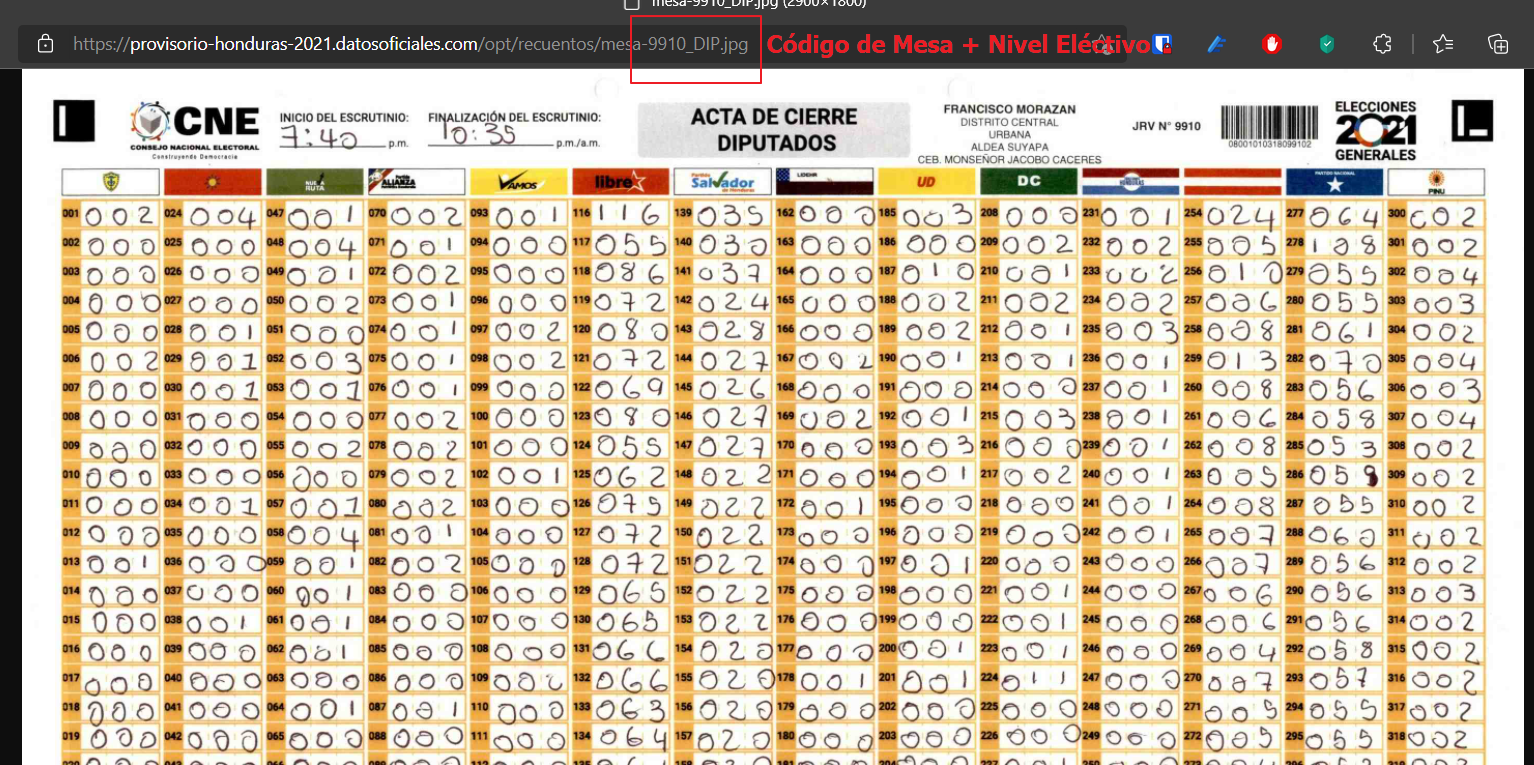
Lo primero que se me vino a la mente, fue revisar las imágenes. Para sorpresa de nadie, las imágenes están en un repositorio y se accede a ellas mediante el enlace (No puede encontrar la manera de ver todo el folder de imágenes). Ese link es algo particular, ya que tiene el número de mesa y el código del nivel electivo:
Por lo que, para ver los archivos de las actas, basta con modificar ese enlace para cambiar la imagen. Con un ciclo For que cambie ese texto basta para realizar esto. Es decir, si quiero ver el acta 1000 para diputados, basta con cambiar el enlace de la imagen de esta manera: https://provisorio-honduras-2021.datosoficiales.com/opt/recuentos/mesa-1000_DIP.jpg
Primer paso finalizado, ahora la tarea es obtener la data. Asumí que estaban utilizando un servicio REST para esto. Así que con ayuda del navegador, mire las peticiones que se hacía el momento de refrescar una página y encontré lo siguiente:
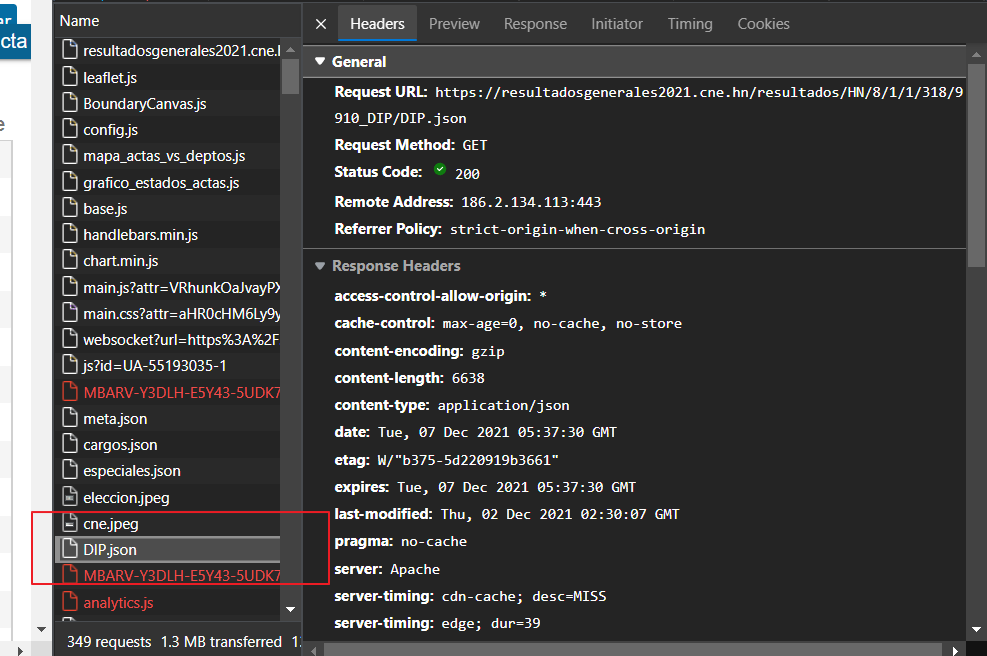
Al abrirlo me alegré, pero al mismo tiempo encontré un problema. Efectivamente era la información que necesitaba, pero la forma en la que se formaba el enlace para la petición utilizaba una codificación la cual, le encontré algo de sentido, pero tenía que encontrar alguna forma de obtenerla. Este enlace tenía una combinación de País, código de departamento, código de área, código de colonia y código de mesa, lo cual al carecer de esta información complicaba algo la extracción.
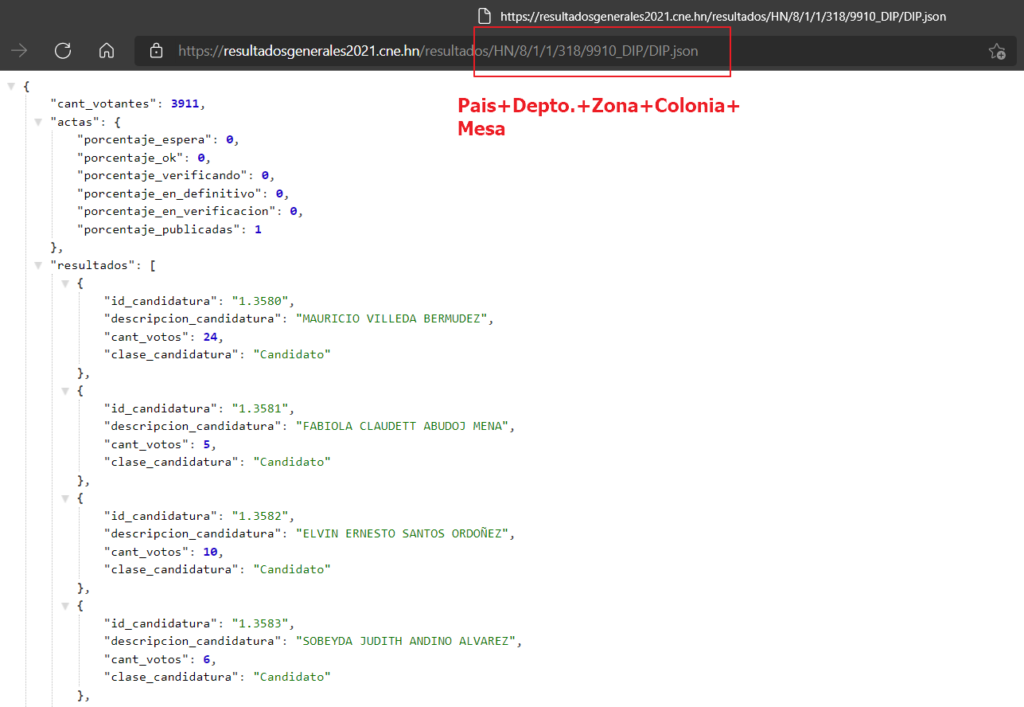
Pero si algo me llamo la atención, es que era la misma codificación del filtro de la página principal. Por lo cual, encontrar como se llenaba ese filtro era una prioridad y al buscar nuevamente en los request de mi máquina encontré esta maravilla:
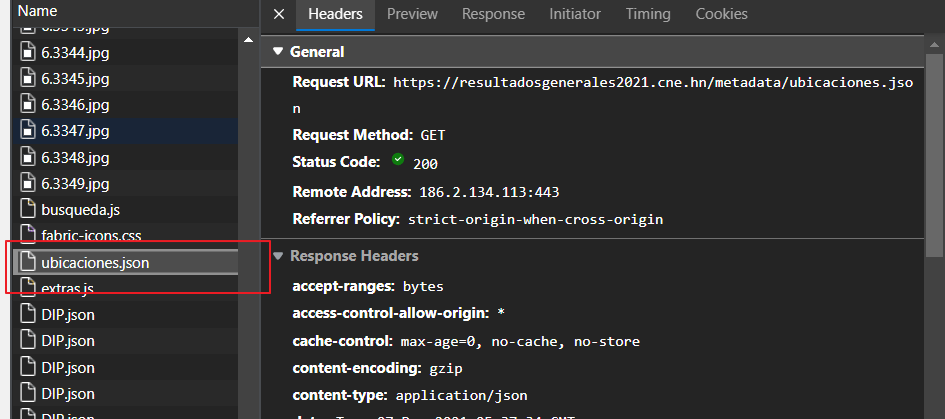
¡Voila!, era el archivo que necesitaba, ya con esto basta recorrer este archivo para crear los enlaces de forma dinámica y listo.

Desarrollo
Para estos scripts, decidí usar un lenguaje que he usado muy poco: Python. ¿Por qué?, principalmente para practicar y segundo porque consumir servicios Rest es algo más sencillo en lenguajes donde no se declara el tipo (En un futuro explicaré los beneficios de estos). Pues instalé la última versión de Python y el Plug-In de Visual Studio Code para desarrollar. Si quieres descargar o ver el código lo puedes ver acá.
Primeramente, para descargar las imágenes hice una petición por HTTP creando el enlace de forma dinámica, la recibía como texto y escribía el binario de la siguiente manera:
if r.status_code == 200:
r.raw.decode_content = True
with open(completeName, 'wb') as file1:
shutil.copyfileobj(r.raw, file1)Ese fue el primer script, para el segundo simplemente me dediqué a parsear la petición y escribí un archivo .CSV para importarlo en RDBMS.
data = response.json()
registro = ''
idPublicacion = data['id_publicacion']
idUbicacion = data['id_ubicacion']
cantVotosPositivos = data['cant_votos_positivos']
totalVotos = data['cant_votantes']
resultadosData = data['resultados']
departamento = str(codigoArreglo[1])
for candidatoResultado in resultadosData:
nombreCandidato = candidatoResultado['descripcion_candidatura']
votosCandidato = candidatoResultado['cant_votos']
claseCandidatura = candidatoResultado['clase_candidatura']
idCandidatura = candidatoResultado['id_candidatura']
if claseCandidatura != 'Especial':
partido = idCandidatura.split('.')[0]
else:
partido = idCandidatura
registro = str(idPublicacion) + '|' + idUbicacion + '|' \
+ str(cantVotosPositivos) + '|' + str(totalVotos)
registro = registro + '|' + nombreCandidato + '|' \
+ str(votosCandidato) + '|' + claseCandidatura + '|' \
+ str(partido) + '|' + departamento + '\n'
toFile = toFile + registro
file1 = open(completeName, 'w')
file1.write(toFile)
file1.close()
Testing
Cuando inicié a correr el script de las imágenes no tuve problema alguno, me funcionó correctamente. Sin embargo, el Script de la petición me devolvía un HTTP Error 403, incluso me fui al postman para revisar y obtuve el mismo resultado:

Al principio no entendía el problema. Pero el gobierno siempre trata de complicar todo. Añadieron una validación para que solamente se puedan hacer este tipo de consultas desde un navegador. Un navegador incluye Headers por defecto y esto es lo que revisa la petición. Proseguí por agregarlos al Postman para verificar si funcionaba yyyyyy:

Funciono correctamente, agregué esos headers a mi código de python de la siguiente manera:
response = requests.get(link, stream=True, headers= {"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8", "Accept-Encoding":"gzip, deflate, br", "Accept-Language":"en-US,en;q=0.5", "Cache-Control":"max-age=0", "Connection":"keep-alive", "Cookie":"ak_bmsc=EAE71489EBA6E9BC9200358D8FB48F45~000000000000000000000000000000~YAAQZYYCugPODVJ9AQAAMlG8gw5ZLMIaoM1RCwpDMVH13V0ksSj+3kreTsh4IsxiHTIaNmW8h8Rw2ZSHUnTAlfUh8rJrFy2nLHFLr0epZQwBNU+kFUBWpj/NVjywRlFxM1LcSteCYoprS3hq4GoHKJ0PMysF/gHxG1Js09u90akTlParhQwwCuquSONyRvGz9uCIf1vHKidmrXSZWF1zGUHvj1Azj5LamHj99VVTVJq+qQOCXo4c/Z+eD3TQnqXbcHVxD92unkGE73lUAyrJESuheAHW0Q90FD7wO6zRytCt+9jm83zc3xpM0+9zaFFI1bRXaRmkpF5qHqPzpR6WwTiraokMFVS6iB80+djSv0ie0E2pJz5F+K3Rh9F3Zv7c9tqAnnOGBmL1/qGZmBGLDk53s7l7rZXLQcEWKhFaoA==; bm_sv=A3B3A9F405246F92AB46B4F726AF138F~fArgEXdPJEtXqZTm3A7CulczuYw6hzdvSnvN0lVJJPCjEcDt/wtr0x5SPpKcR63ADu5Dq8V+4bfe99ERjqFzGzNTLaQygKDAu4TaqMhVNI6UrL2o7ACTIvcd1mNl/t7eotUPqF2r4sHBpts07a4n/n2BD7jC8e5ctP7sEEtac6WhBtx6iAqPU4XCWnqYfGso", "Host":"resultadosgenerales2021.cne.hn", "Sec-Fetch-Dest":"document", "Sec-Fetch-Mode":"navigate", "Sec-Fetch-Site":"none", "Sec-Fetch-User":"?1", "TE":"trailers", "Upgrade-Insecure-Requests":"1", "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0"})Y terminó, el proceso de descarga de imágenes tardó aproximadamente 3 horas (Son 6 GB de imágenes hasta ese momento) y el proceso de petición para la data estuvo unas dos horas. Con algo de creatividad, todo se puede.

Conclusión
Realmente, si el gobierno tenía la intención de complicar obtener la información, no hizo mucho trabajo para esto. Si no fue la intención, igualmente complican a los que son más inexpertos en estos temas. Esta información debería ser de fácil acceso para cualquier ciudadano, por lo cual, dejó este código por si alguien está interesado en revisar la información.
«Solo el que construye el futuro tiene derecho a juzgar el pasado»
Friederich Nietzche
Edit: 2021/12/07 21:43
Un comentario me pidió si era posible realizar un video tutorial para correr los scripts en su computadora. Como este Blog es para facilitar todo, decidimos realizarlo. Acá dejamos el enlace del video.

Esta ciertamente detallada,explicita la data,aun,para algun@s o muchos que tenemos mu poca o casi nula formacion en informatica,sistemas o demas,es algo o poco digerible lo expuesto,observado,si bien,nos enviase n,SI SE PUEDE,en el tiempo necesario u oportuno algun tutorial,ademas de lo dado,recibido. Muy agradecido s,ASI AVANZAMOS,SE CONSTRUYE, REFUNDA MATRIA-PATRIA.
Muy buenas tardes estimado. Por la noche intentaré hacer un video explicando como ejecutar cada uno de los scripts, para que puedan ser utilizados por su parte. Gracias por su comentario.
Listo Estimado Angel. En el Post puede visualizar un video donde explico cómo utilizar los Scripts. Esperamos que sean de utilidad.
Saludos y ¡Hasta la Victoria Siempre!